AirExo
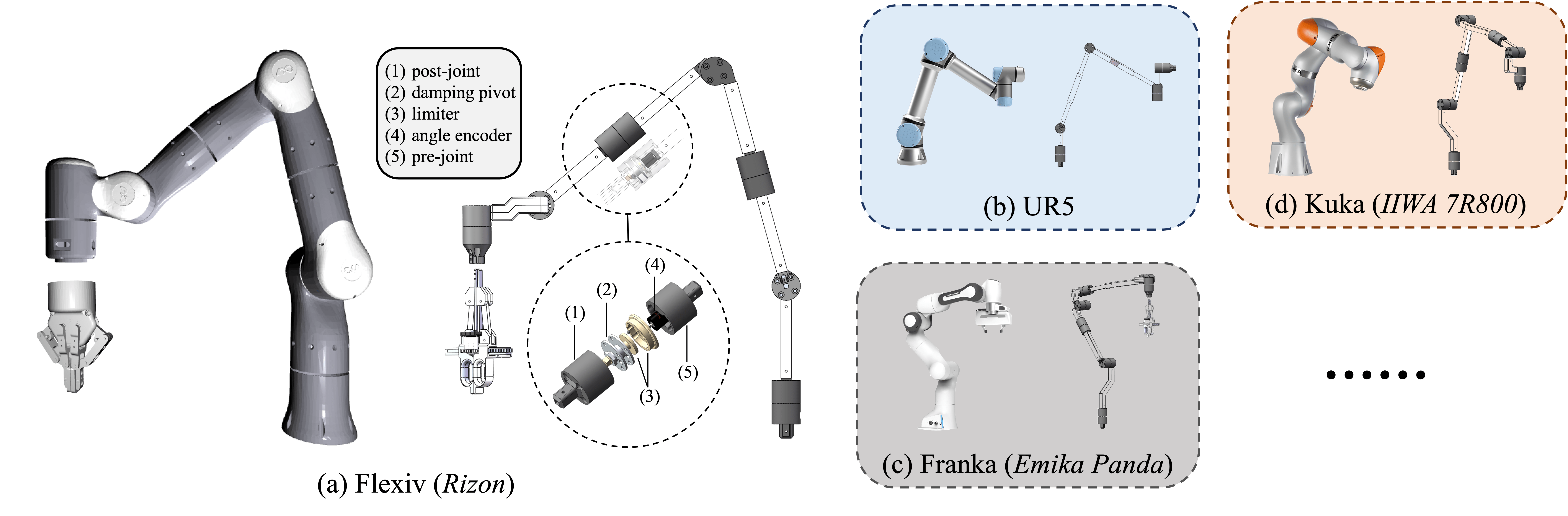
We introduce AirExo, an open-source, portable, adaptable, inexpensive (approximately $300 per arm), and robust exoskeleton system. The system is initially developed for Flexiv Rizon arms, and it can be quickly modified for different robotic arms, such as UR5, Franka and Kuka.
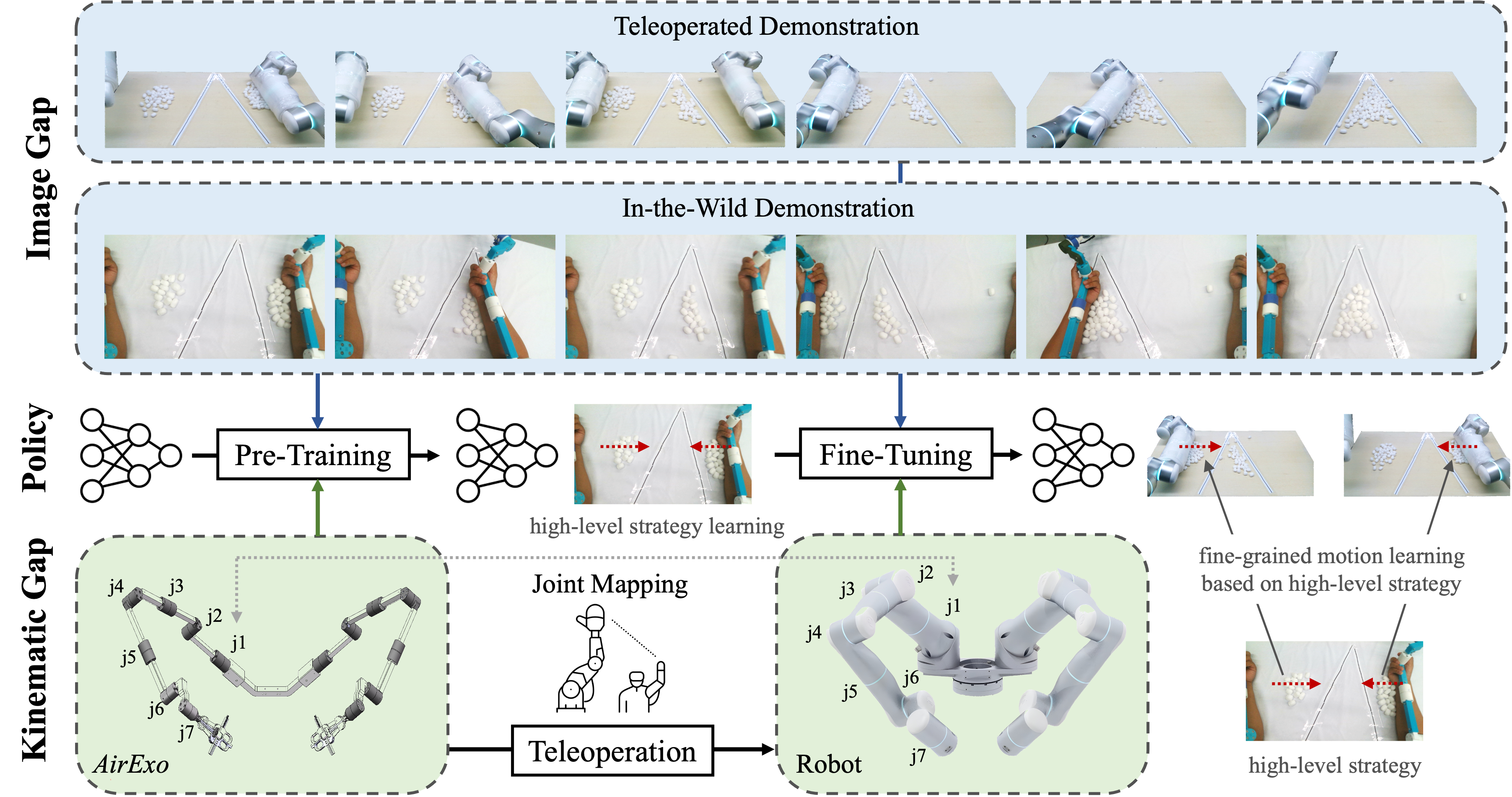
After calibration with a dual-arm robot, AirExo can achieve precise joint-level teleoperations of the robot for teleoperated demonstration collection.
Moreover, contributed to its portable property, AirExo enables in-the-wild data collection for dexterous manipulation without needing a robot. Humans can wear AirExo, conduct manipulation in the wild, and collect demonstrations at scale. The one-to-one joint mapping also reduces the barriers of transferring policies trained on human-collected data to robots.
This breakthrough capability not only simplifies data collection but also extends the reach of whole-arm manipulation into unstructured environments, where robots can learn and adapt from human interactions. In the future, we are excited to see our AirExo collecting large-scale demonstrations in unstructured environments and facilitating robot learning.